slam.csv
player,sex,oa,rg,wim,us
Rafael Nadal,M,2,14,2,4
Novak Djokovic,M,10,2,7,3
Roger Federer,M,6,1,8,5
Pete Sampras,M,2,0,7,5
Magaret Court,F,11,5,3,5
Serena Williams,F,7,3,7,6
Steffi Graf,F,4,6,7,5
Helen Wills,F,4,0,8,7Well, for those who follow me, you probably know my enthusiasm for data science in general and wrangling in particular.
So every time I find a new tool, command, language, or other, likely to help me in my workflow, I am always eager to dive into it even if the tools I currently use provide a solution to the problem I am trying to resolve.
To be clear, I had no plan to leave the {tidyverse} universe, neither today nor tomorrow. {dplyr} and co are more complete and recent improvements only increase my love for the ecosystem.
Let’s talk about Miller or mlr, defined by the official docs as:
Miller is a command-line tool for querying, shaping, and reformatting data files in various formats including CSV, TSV, JSON, and JSON Lines.
Miller is pretty useful for format conversion, data manipulation, columns selection, mutating, renaming … and more (pre)post-processing operations using command line.
A detailed and more complete visit guide is available on the official documentation site. Here, I will be more concise, presenting only some methods that I have found useful if we want to quickly perform wrangling operations without opening RStudio, jupyter notebook or any other development environment.
For Lunix users: apt-get install miller or yum install miller
For MacOS users: brew update and brew install miller
For Windows users and other installation options including from a docker image that you can check here.
To browse the different commands, let’s copy paste this data into a file slam.csv
slam.csv
player,sex,oa,rg,wim,us
Rafael Nadal,M,2,14,2,4
Novak Djokovic,M,10,2,7,3
Roger Federer,M,6,1,8,5
Pete Sampras,M,2,0,7,5
Magaret Court,F,11,5,3,5
Serena Williams,F,7,3,7,6
Steffi Graf,F,4,6,7,5
Helen Wills,F,4,0,8,7The first command we will see is mlr cat for “data reading”. mlr cat is analog to cat command and used to print (read) our data.
mlr cat slam.csvThe result will look like that:
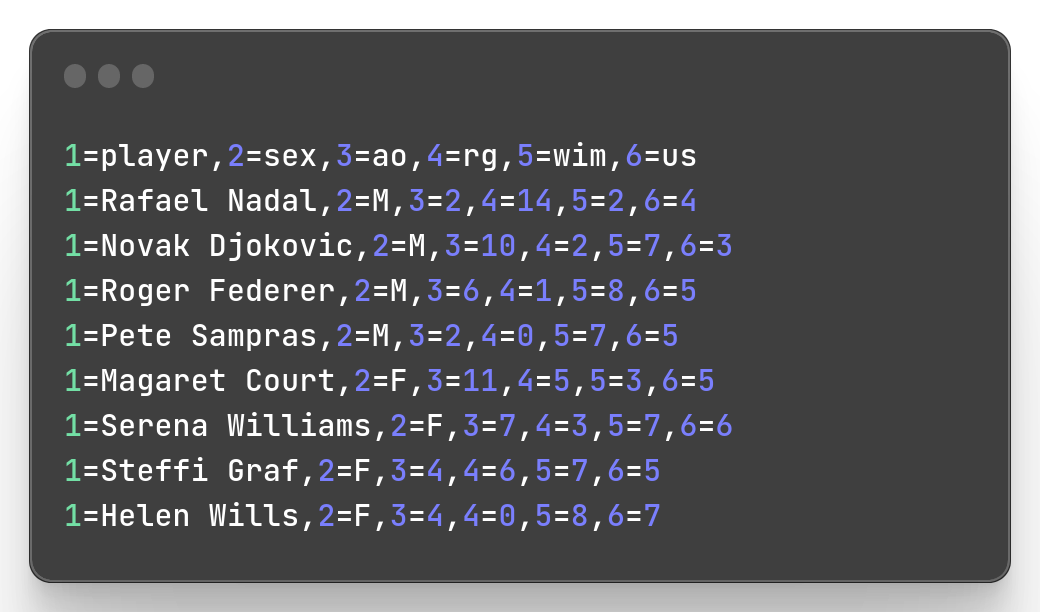
If you look ar the printed result, it doesn’t look like the main slam.csv. This is because we don’t specify to Miller the way (the format of the output) we want it to display our input data. We can remedy to that with the command argument --ocsv (for output csv). We can also precise the format of our input file with --icsv (for input csv) .
mlr --icsv --ocsv cat slam.csv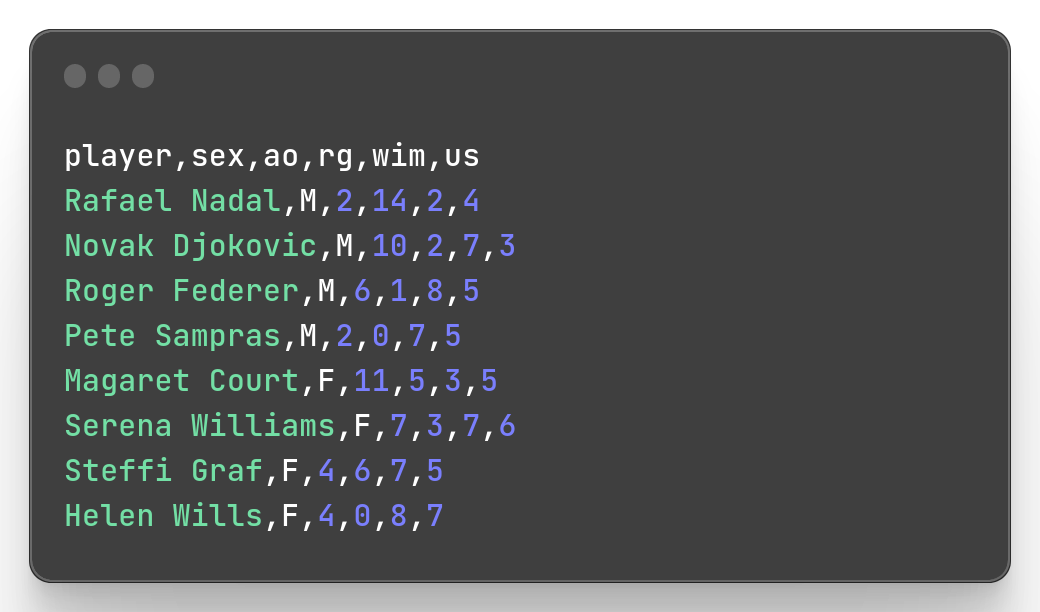
Since our input and output have the same format, we can replace --icsv --ocsv with just --csv.
mlr --csv cat slam.csvOf course, we are not limited to csv format. Many other formats that are supported: json, tsv, asv, usv ..etc. There is also a pprint format for pretty print which as you might guess, pretty print.
mlr --icsv --opprint cat slam.csv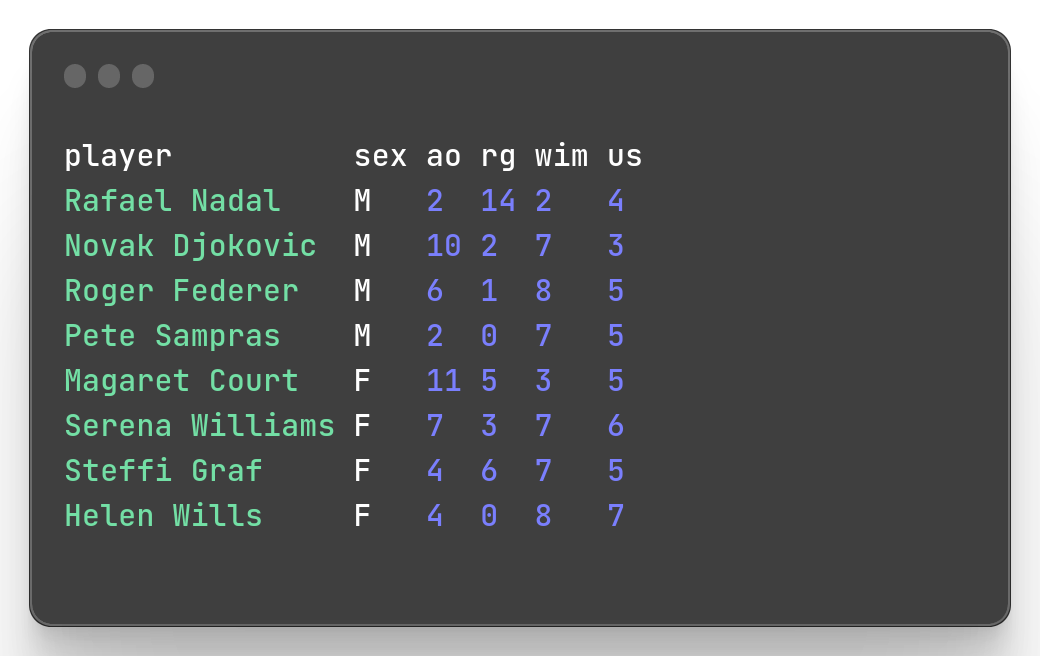 So you can combine different input and output formats to convert your data file format.
So you can combine different input and output formats to convert your data file format.
mlr --icsv --ojson cat slam.csv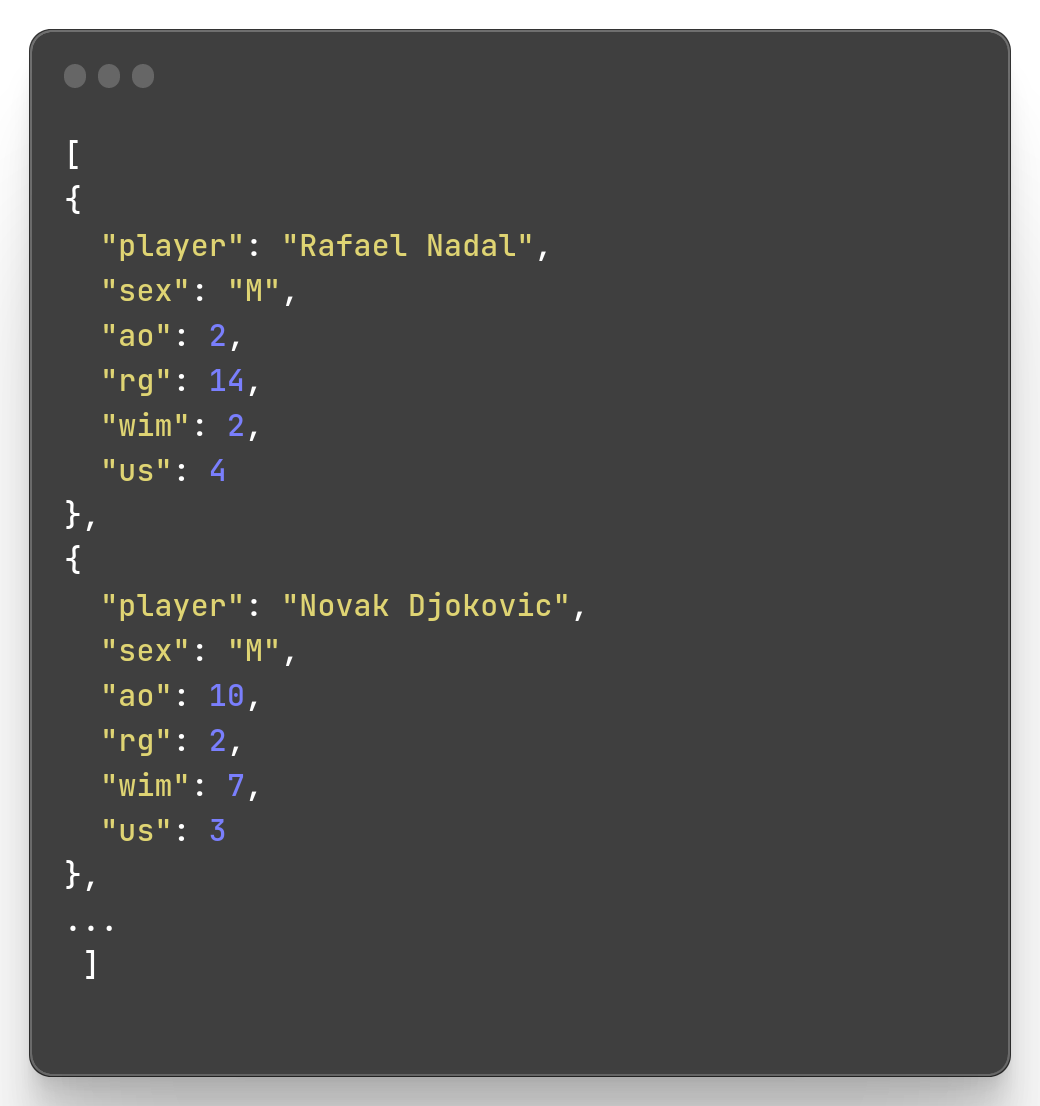
As with many commands, it can be tedious to remember that you must specify the data file at the end of your command, so there is also an --from argument to explicitly specify the file path.
mlr --from slam.csv --csv catLet’s suppose you have the next group of slams winners in a file slam_next.csv
slam_next.csv
player,sex,ao,rg,wim,us
Roy Emerson,M,6,2,2,2
Rod Laver,M,3,2,4,2
Bjorn Borg,M,0,6,5,0mlr cat offers you the possibility to link and display the 2 datasets together.
mlr --icsv --opprint cat slam.csv slam_next.csv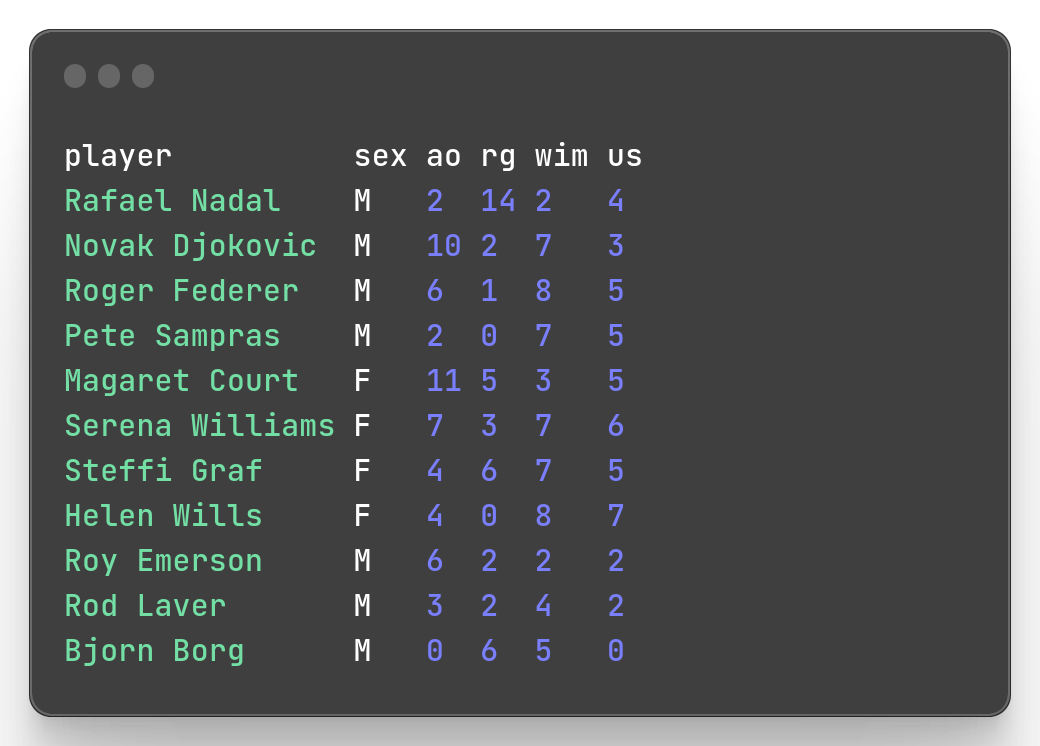
With cat command the header will be duplicate.
To output part of our data file, Miller provides mlr head et mlr tail with the same logic as tail and head commands. Those commands, as well as semantically well-named functions return the first records and the last records respectively.
mlr --icsv --opprint --from slam.csv head -n 3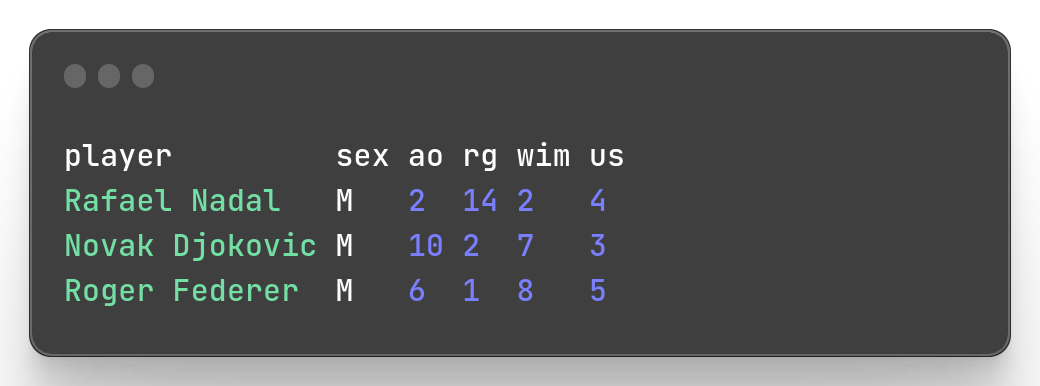
mlr --icsv --opprint --from slam.csv tail -n 3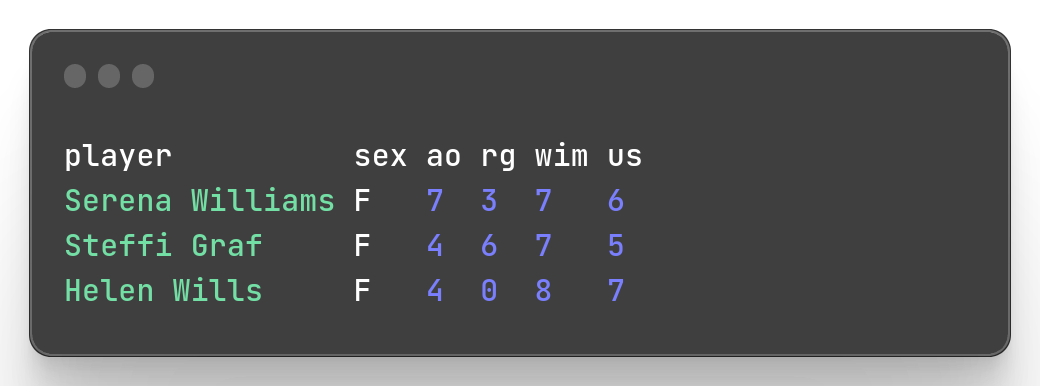
mlr sort is the Miller version of arrange() function for users from R package {dplyr}. To sort the data of a column col1 with string values, you can specify it with the -f flag. To sort from a column col2 with numeric values, you can specify it with -n flag, then the data is sorted in ascending order. To sort in descending order, you can add -r flag, or more compactly with -nr flag.
Examples:
mlr --icsv --opprint --from slam.csv sort -f player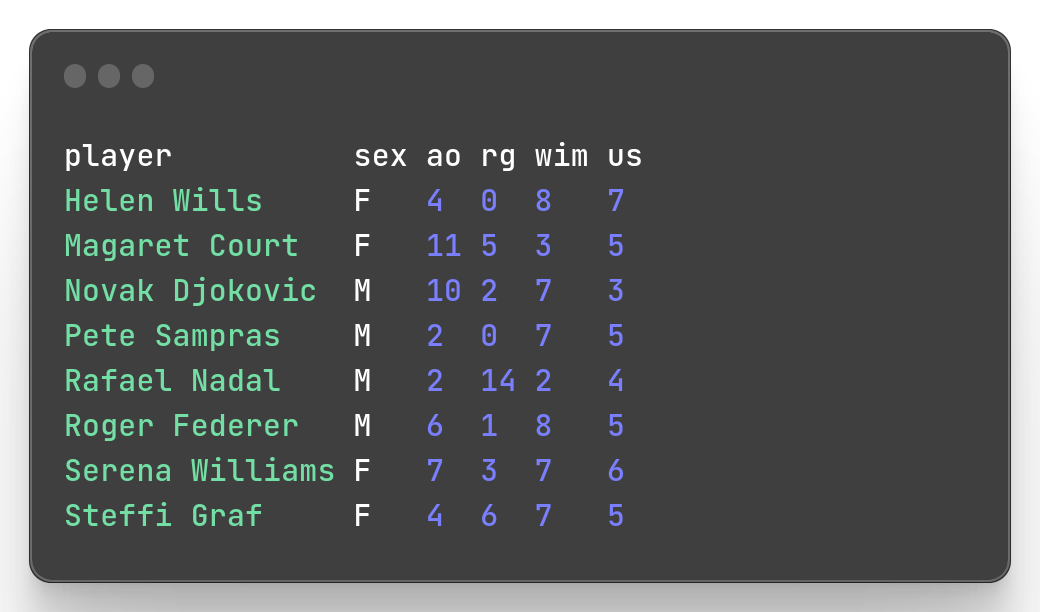
mlr --icsv --opprint --from slam.csv sort -n oa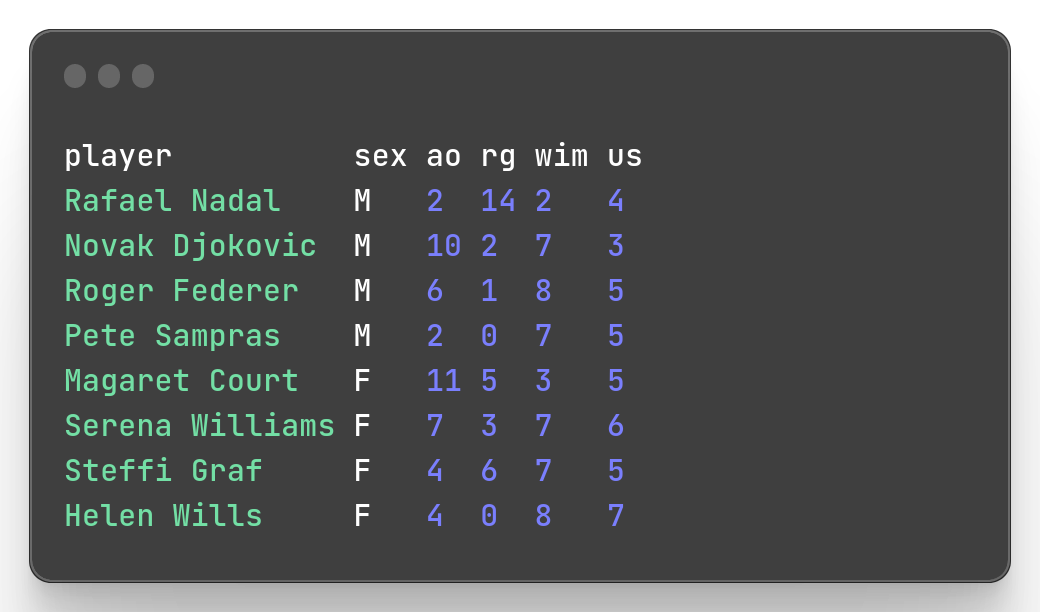
rg column)mlr --icsv --opprint --from slam.csv sort -nr rg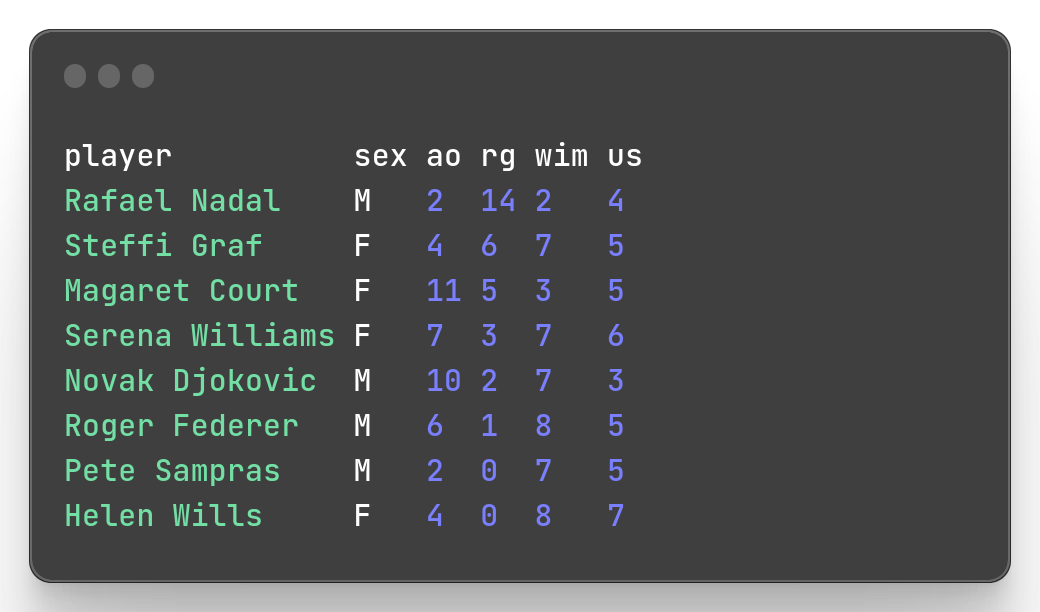
You can combine multiple sorting operations
Example: Sort descending by the number of US Open won (us column), then descending by the number of Wimbledon won(wim column).
mlr --icsv --opprint --from slam.csv sort -nr us,wim 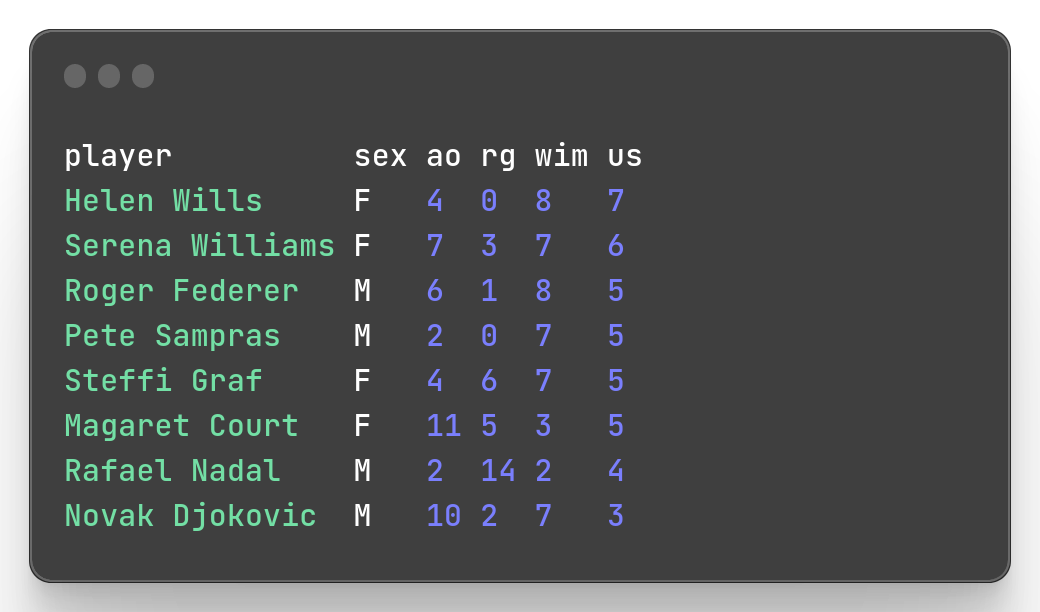
Note that here, I separate the numerical columns by a comma as I do the same sorting operations on the 2 fields.
Now let’s do sorting operations with different orders.
Example: Sort descending by the number of US Open won (us column), then ascending by the number of Wimbledon won
mlr --icsv --opprint --from slam.csv sort -nr us -n wim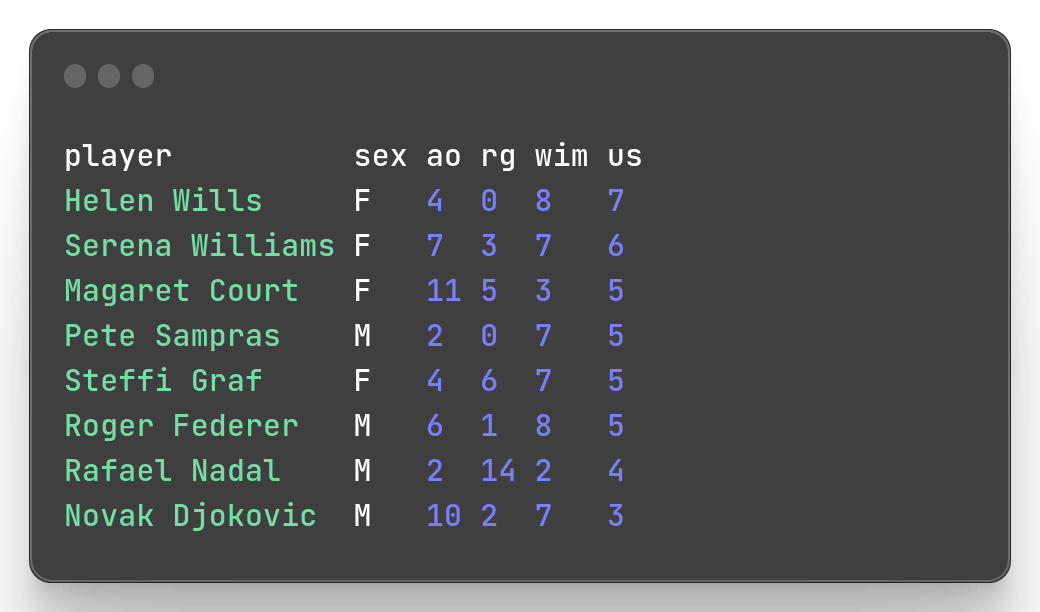
To sort a field with a space in its name, you must enclose the field name in single quotes. It is very important to disambiguate and prevent the interpreter from evaluating each split terminology as a command argument. To illustrate this, let’s rename column ao to “Australian Open” and place the dataset in a second csv file slam_2.csv. Don’t be surprised if you don’t understand this command line at first glance. I will talk about renaming with Miller below.
mlr --csv --from slam.csv put '$[[3]] = "Australian Open"' > slam_2.csvWell, now we have the column “Australian Open” having its name with a space. Let’s sort descending with that column.
mlr --icsv --opprint --from slam_2.csv sort -nr 'Australian Open'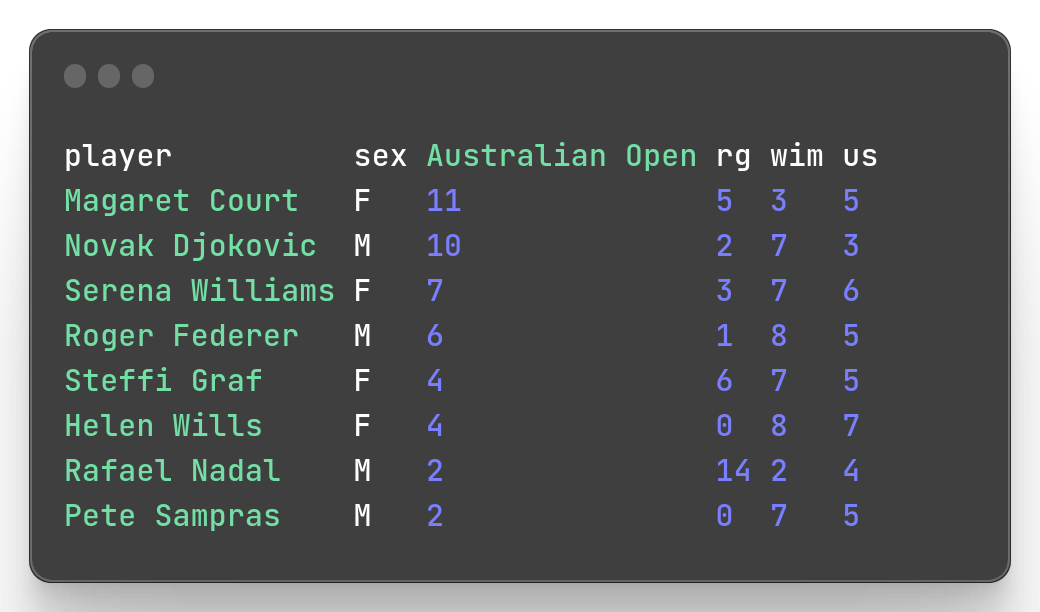 Pretty good, we sort a column with a space in its name.
Pretty good, we sort a column with a space in its name.
mlr cut is used to select only some fields.
mlr --icsv --opprint --from slam.csv cut -f sex,player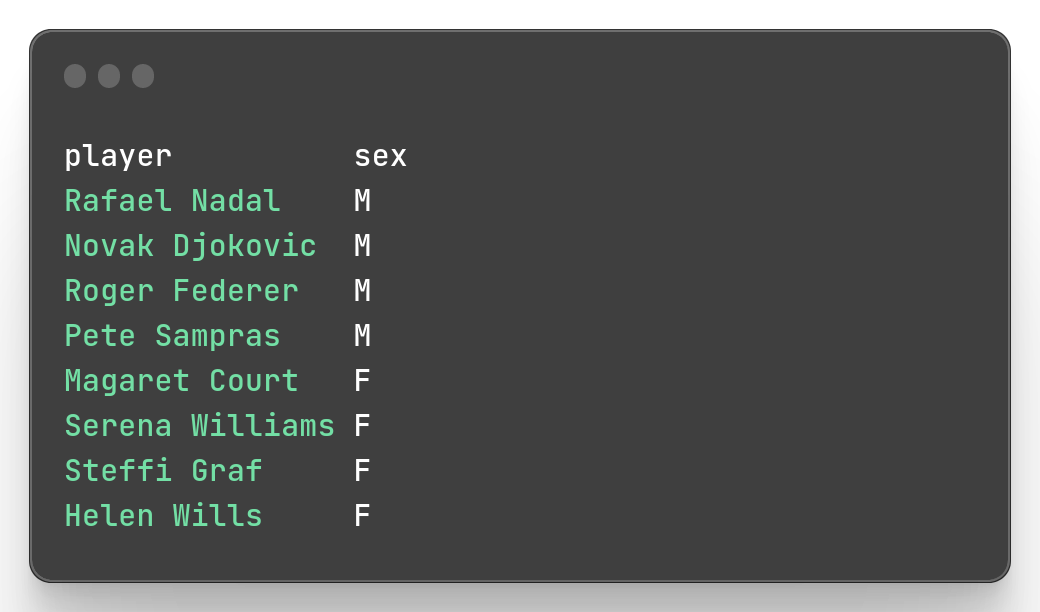
To force the output to be in the order you make the selection you can use the flag -o.
mlr --icsv --opprint --from slam.csv cut -o -f sex,player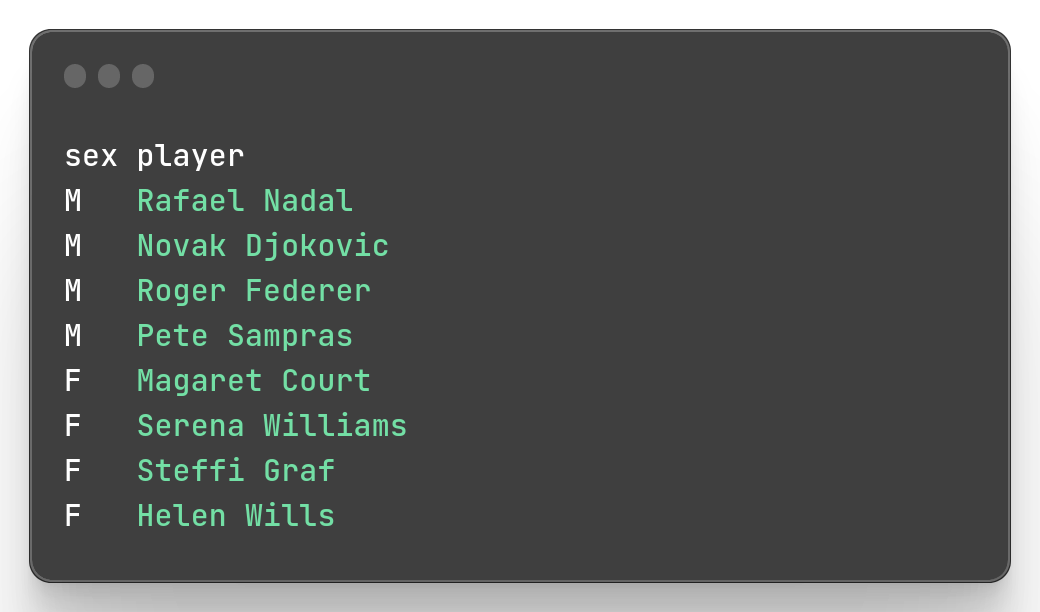
You can also choose to select all columns except some with -x flag.
mlr --icsv --opprint --from slam.csv cut -x -o -f us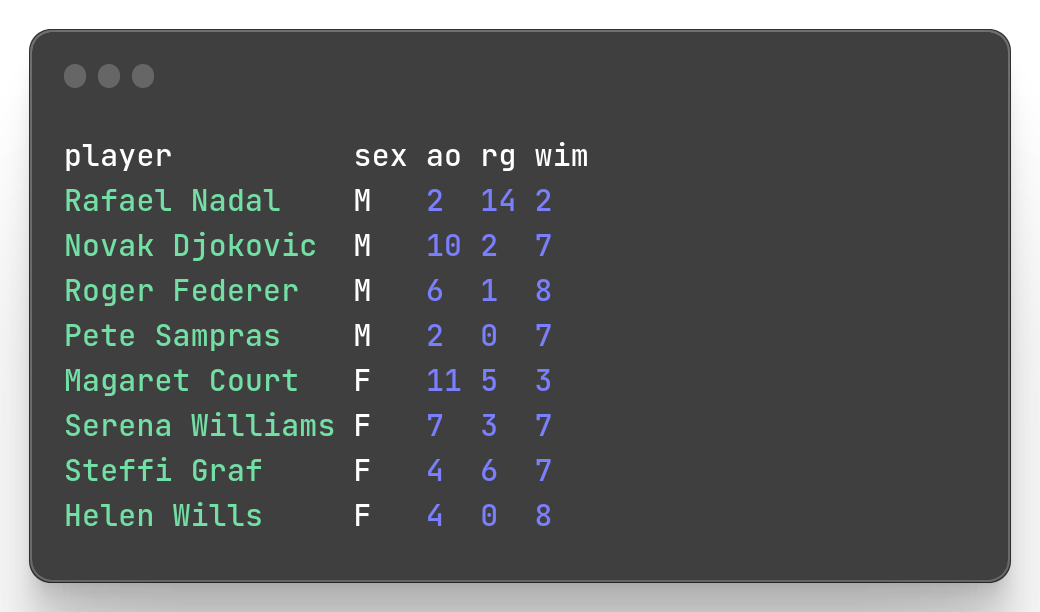
Example: Rename the column ao to australiano
mlr --icsv --opprint --from slam.csv put '$[[3]] = "australiano"' 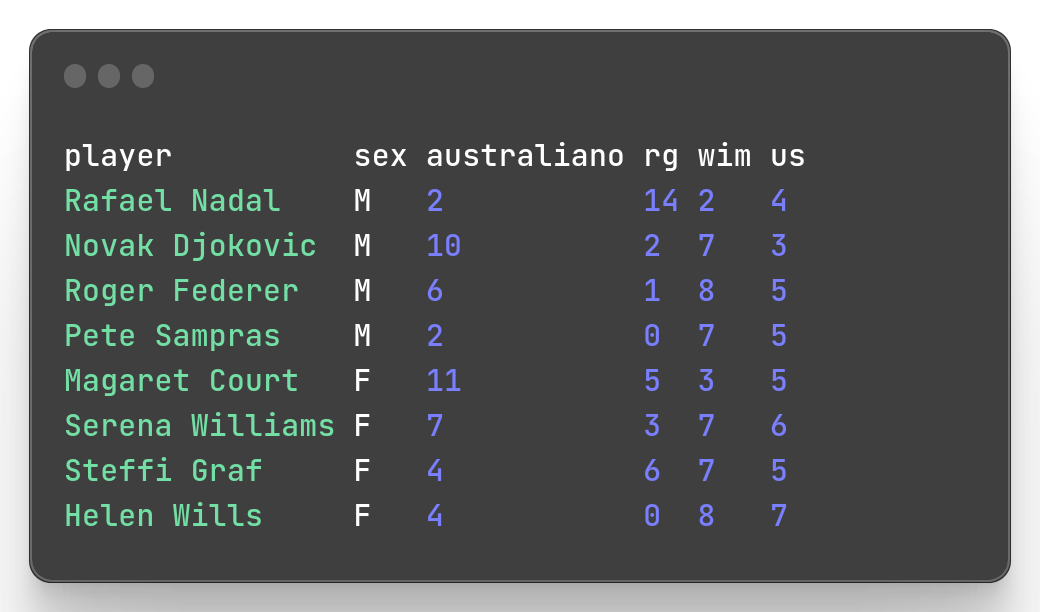
Note that for the renaming of the column I use its index, here 3 in the expression $[[3]]. If my goal was to mutate the column values, I would use 3 box brackets instead.
mlr --icsv --opprint --from slam.csv put '$[[[3]]] = 0' 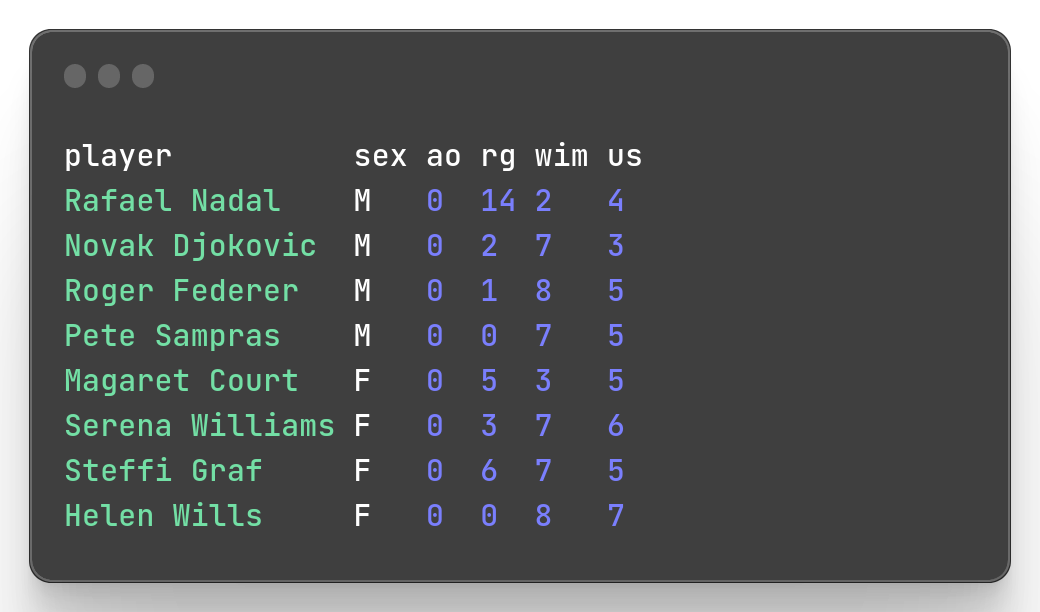
To create a new field we also use mlr put command.
mlr --icsv --opprint --from slam.csv put '$total = $ao + $rg + $wim + $us'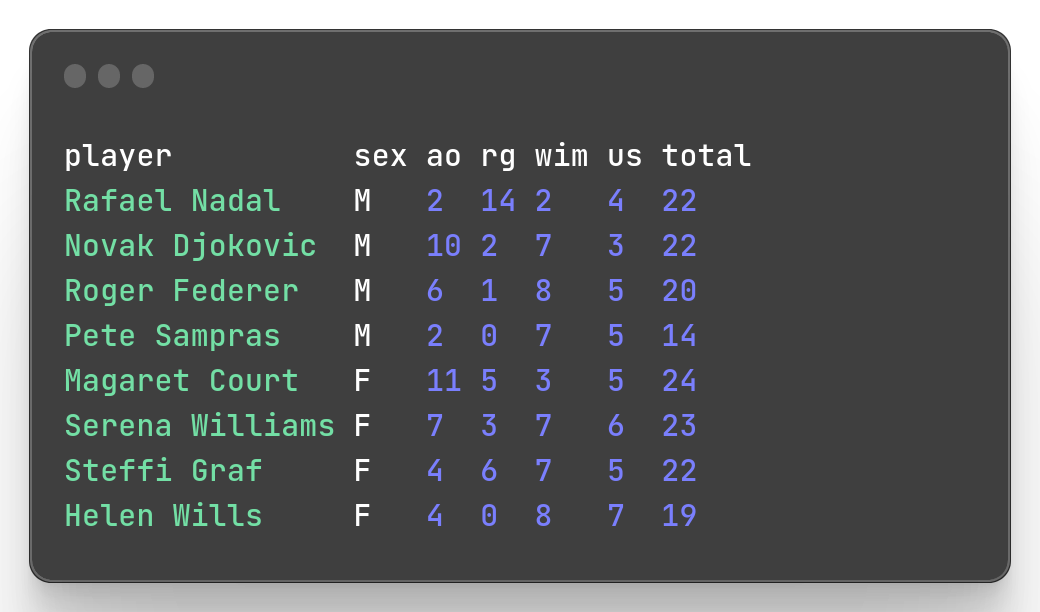
You can create a new field and use it immediately in a subsequent field creation statement.
Example: Let’s define the proportions of Roland Garros titles in players success count.
mlr --icsv --opprint --from slam.csv put '$total = $ao + $rg + $wim + $us;$rg_ratio = ($rg/$total)*100;'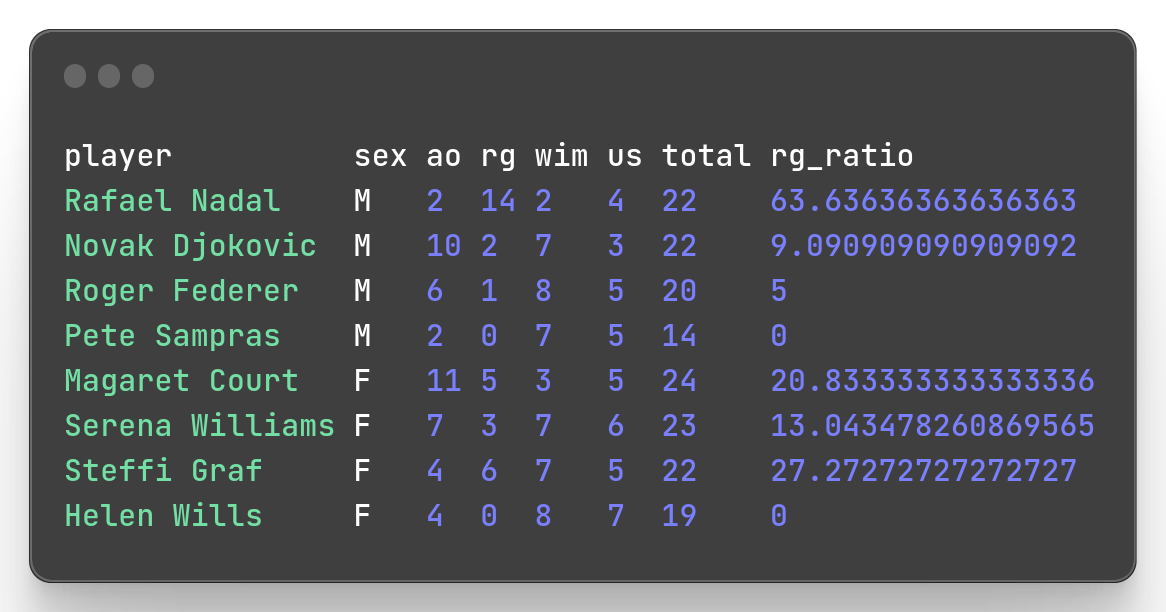
If we want to create a column with a space in its name, I have to surround the name with a brace. Example: Let’s create a “Total titles” column to count the total number of slams by player.
mlr --icsv --opprint --from slam.csv put '${Total titles} = $ao + $rg + $wim + $us;'No filter, no data wrangling, so Miller comes with its filter utility requiring a logical expression to know the dataset records to keep and which to move.
Example: Let’s just keep the women in our champions dataset.
mlr --icsv --opprint --from slam.csv filter '$sex == "F"'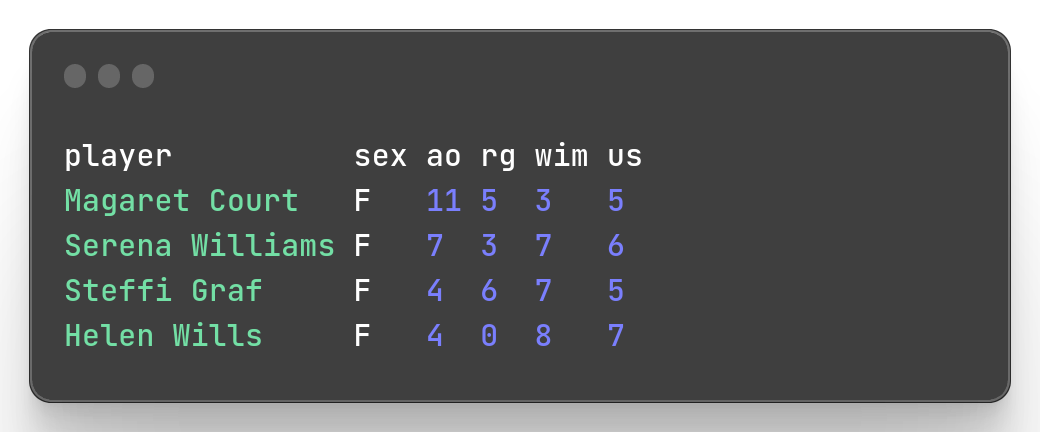
Of course we can chain multiple logical expressions to be evaluate.
Example: Let’s just keep the men with more than 5 Wimbledon titles
mlr --icsv --opprint --from slam.csv filter '$sex == "M" && $wim >= 5'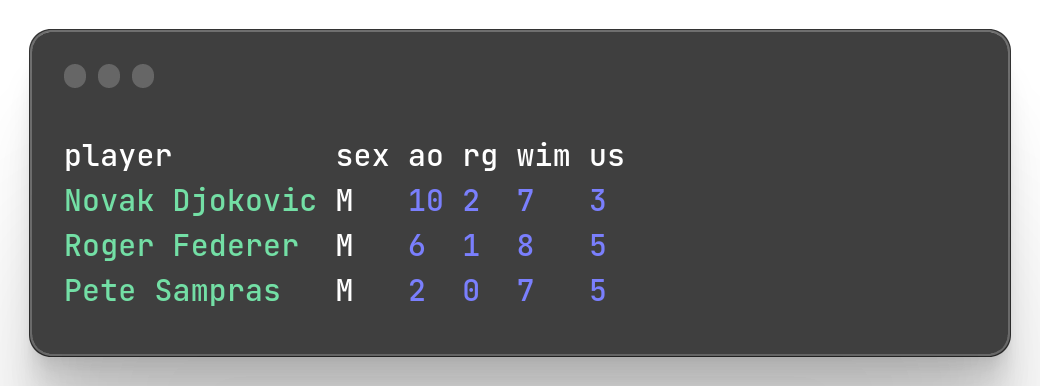
To filter a column with a space in its name, you can also use the brace here. Let’s illustrate this with our second slam_2.csv file by filtering out athletes with a total number of Australian open greater or equal to 6.
mlr --icsv --opprint --from slam_2.csv filter '${Australian Open} >= 6'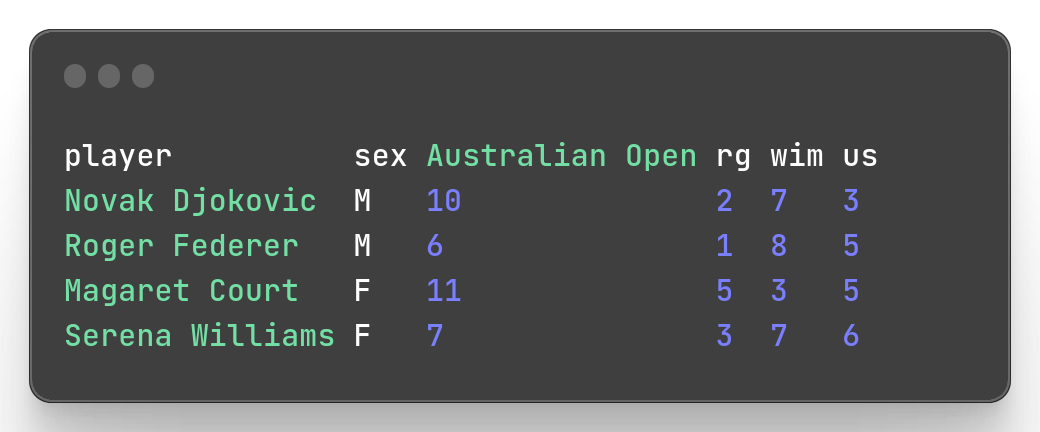
What I really like about with the modern data analysis with R workflow is the ability to chain multiple with the pipe operator. You filter then you mutate then you select then you rename and … . Miller also offers this possibility by 2 ways. The first one, the traditional | operator.
Example: Let’s suppose we want the 3 athletes with most Wimbledon titles.
You can sort in descending order by wim column and then chain we with a selection of the first 3 lines.
mlr --icsv --opprint --from slam.csv sort -nr wim | mlr --icsv --opprint head -n 3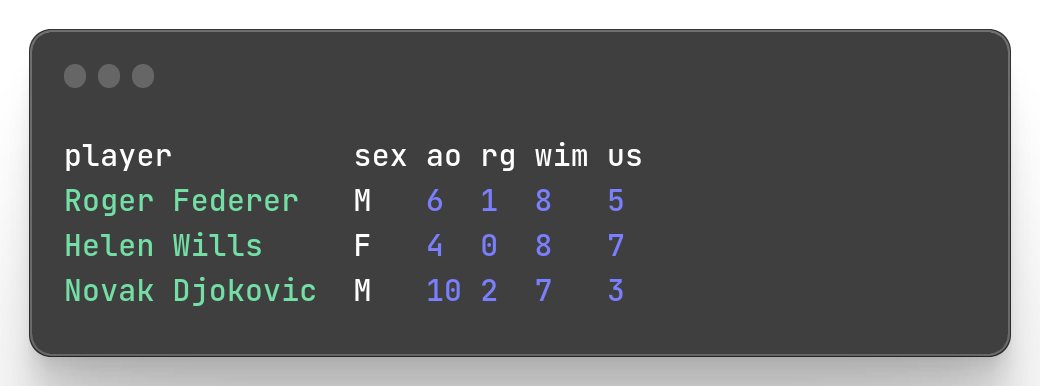
For those familiar with the line command | operator (I am not), this should be natural.
Fortunately Miller provides a second way to do so. It is with the verb then. I do this operation then I do that second operation then a third operation and so on.
Let’s rewrite the previous query.
mlr --icsv --opprint --from slam.csv sort -nr wim then head -n 3 then cut -f player,wim
then is an internal Miller pipe, so we just need to invoke once that we use mlr command.
To group by column values, Miller provides -g flag that you can apply to a column. For example, let’s select the champions with most Wimbledon titles by gender.
mlr --icsv --opprint --from slam.csv sort -nr wim then head -n 1 -g sex
Let’s try a more complex chaining by selecting the champions with the most titles overall by sex.
mlr --icsv --opprint --from slam.csv put '$total = $ao + $rg + $wim + $us;' then sort -nr total then head -n 1 -g sex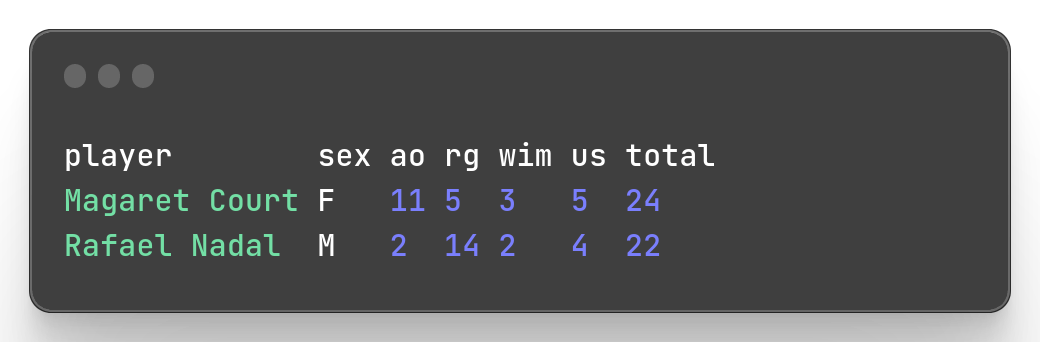
Well it returned the champions with most title by gender, Rafael Nadal for men with 22 titles, Magaret Court for women with 24 titles, but it didn’t return Novak Djokovic who at the moment I write this post has the same number of titles as Rafael Nadal. This is because I only return the first with head -n 1 and Rafael Nadal appears first in our dataset. I am not sure if Miller has an option acting like with_ties parameter from slice_max() method from {dplyr} package.
Let’s now compute statistics to close this Miller guide tour. The verb used to invoke stats functions is stats1. I l should be combined with -a flag to specify the statistics functions we want to apply on columns, -f to define the columns on which we want to apply the functions and -g for the column values we want to group by. The available functions I found are: count, min, max, mean.
Example: Let’s compute the number of number of players by gender, the number min, mean, max of Roland Garros they won.
mlr --icsv --opprint --from slam.csv stats1 -a count,min,max,mean -f rg -g sex 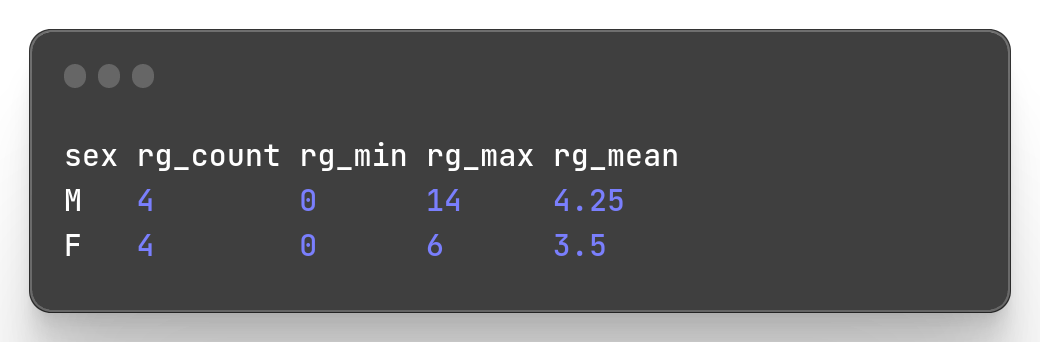
Pretty well, it calculated the statistics the way we wanted.
Of course, this guide is a fairly quick tour of some appetizer offerings that Miller gives us in an exploratory data analysis process. The utility offers more features, to accomplish more complex wrangling tasks, including its own programming language.
From perspective of a data science enthusiast, the tool is ideal for those who frequently need to transfer data from one defined format to another, quickly select, filter, sort, compute basic mathematical operations. The tool can show some limitations when it comes to easily pivoting, splitting, expanding columns or doing functional programming stuffs, but truth to be told I didn’t expect it to do that and I won’t ask it to. Miller ticks all boxes I would expect from a data file query command line tool. So, as I will be using it a quite a bit over the next months, I will be keeping a frequent lookout for new features that open sources folks developing it will drop.
I use field and column terminologies interchangeably.↩︎
@online{issabida2023,
author = {Abdoul ISSA BIDA},
title = {Mlr},
date = {2023-04-08},
url = {https://www.abdoulblog.com},
langid = {en}
}