Hi everyone and welcome in my second blog post.
For this one, we will cover together two of my favorite disciplines, one in Computer Science, Scraping and the other one in real life, Soccer .
Don’t be disappointed 😄, if you are there only for the final dataviz, you can skip to the next section. I tried to make it as much as clear and simple that I can.
Scraping
So, what website we are going to scrape ?
It will be FiveThirtyEight. They provide data behind some of their articles and charts, including data for Soccer Clubs Predictions.
Unfortunately, the data you can retrieve only cover Club Soccer Predictions and Global Club Soccer Rankings. But our today tutorial data, is based on determining which league club will qualify for UCL1 or which will win the national league.
So, we will scrape it directly, from the league page. For example, to scrape, the probabilities for each club of:
- French Ligue 1, we will scrape it from https://projects.fivethirtyeight.com/soccer-predictions/ligue-1/
- German Bundesliga, we will scrape it from https://projects.fivethirtyeight.com/soccer-predictions/bundesliga/
- English Premier League, we will scrape it from https://projects.fivethirtyeight.com/soccer-predictions/premier-league/
- and so on.
Here is an example of how, the data is presented on their website.
The data is updated daily, what is very interesting because, with some tricky automation, we can follow the evolution of the odds of the clubs to win a season along. But, that is not the subject of this blog post.
Website Page Reading
For the scraping, we need a couple libraries, in particular:
library(tidyverse) # For data wrangling, ggplot2 and friends
library(rvest) # for the scraping
library(janitor) # for the function row_to_namesSo, let’s start our scraping workflow :
league_link <- "https://projects.fivethirtyeight.com/soccer-predictions/premier-league/"
clubs_rows <- league_link %>%
read_html() %>% # Retrieve the complete table
html_element("#forecast-table") %>% # Retrieve only the forecast table
html_elements("tbody .team-row") # Retrieve each row of the tableLet’s me explain a little bit the code.
Firstly, I retrieve the complete page.
league_link %>%
read_html()Secondly, I retrieve the forecasting table, with the function html_element(). So, where #forecast-table comes from?
To be a good web scraper, you must be a good website inspector. Web developers, create websites with logic, and in order to retrieve data from those website pages, we have to make to make us their logic.
To find out how to access the forecast table, you must go to the page we are scraping (here). Right-click on the table we want to retrieve, and then click inspect. The browser will open the inspector.
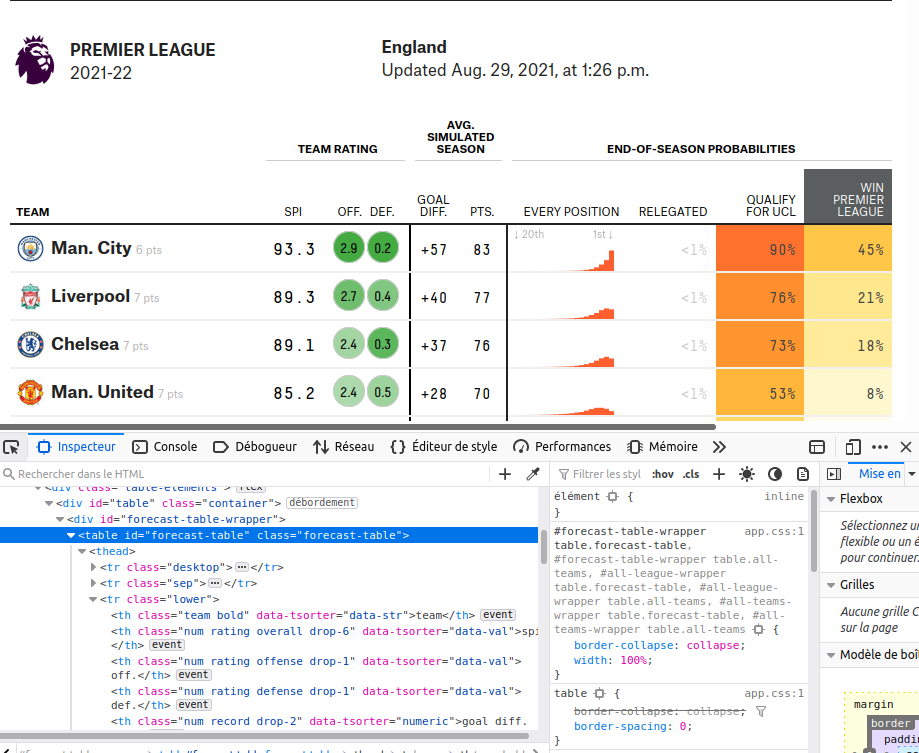
I use Mozilla Firefox as my browser, you will probably need another process depending on your browser. Google it, if you don’t know how to do it.
Next, you need a little attention to notice that the table has as id forecast-table. It also has as class forecast-table. But, we will use the id to access the table.
For this, we use the html_element() function of the rvest(Wickham 2021) package. When we select the table by its id, we prefix the id with # in our html_element() function.
In the same way, we collect each club row with:
... %>%
html_elements("tbody .team-row")Note that we are using, html_elements() instead of html_element(), which selects all the elements (and not just the first one) of our forecast table.
Let’s see what the list of results looks like.
clubs_rows{xml_nodeset (20)}
[1] <tr class="team-row" data-str="Manchester City">\n<td class="team" data- ...
[2] <tr class="team-row" data-str="Liverpool">\n<td class="team" data-str="l ...
[3] <tr class="team-row" data-str="Arsenal">\n<td class="team" data-str="ars ...
[4] <tr class="team-row" data-str="Tottenham Hotspur">\n<td class="team" dat ...
[5] <tr class="team-row" data-str="Chelsea">\n<td class="team" data-str="che ...
[6] <tr class="team-row" data-str="Manchester United">\n<td class="team" dat ...
[7] <tr class="team-row" data-str="Brighton and Hove Albion">\n<td class="te ...
[8] <tr class="team-row" data-str="Newcastle">\n<td class="team" data-str="n ...
[9] <tr class="team-row" data-str="Crystal Palace">\n<td class="team" data-s ...
[10] <tr class="team-row" data-str="Brentford">\n<td class="team" data-str="b ...
[11] <tr class="team-row" data-str="Aston Villa">\n<td class="team" data-str= ...
[12] <tr class="team-row" data-str="West Ham United">\n<td class="team" data- ...
[13] <tr class="team-row" data-str="Leeds United">\n<td class="team" data-str ...
[14] <tr class="team-row" data-str="Fulham">\n<td class="team" data-str="fulh ...
[15] <tr class="team-row" data-str="Southampton">\n<td class="team" data-str= ...
[16] <tr class="team-row" data-str="Wolverhampton">\n<td class="team" data-st ...
[17] <tr class="team-row" data-str="Everton">\n<td class="team" data-str="eve ...
[18] <tr class="team-row" data-str="Leicester City">\n<td class="team" data-s ...
[19] <tr class="team-row" data-str="AFC Bournemouth">\n<td class="team" data- ...
[20] <tr class="team-row" data-str="Nottingham Forest">\n<td class="team" dat ...Well, we have all, the premier league clubs.
Clubs names and logos
The next step in my workflow is to select for each club, its name and logo link. You should be wondering, why I am not selecting the probabilities I was talking at the beginning. Please be patient, this will be the subject of our next section.
Let’s get the name and the logo for one club, and then generalize for all.
# Let's select the first node
node <- pluck(clubs_rows, 1)
team_name <- node %>%
html_element(".team-div .name") %>% # Select Team name elmt
html_text2() %>% # Retrieve the text
# Delete the points in the name
# Example: Man City8pts becomes Man City
str_remove(pattern ="\\d+\\spts?")
team_logo <- node %>%
# Select Team the img which contains team logo
html_element(".logo img") %>%
# Retrieve the the src attribute
html_attr("src") %>%
str_remove("&w=56")Let’s see if everything is what it supposed to.
print(team_name)[1] "Man. City"print(team_logo)[1] "https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/382.png"It is perfect, we can retrieve from a node, the club name and its logo. Let us generalize to all the clubs with a function.
extract_name_logo <- function(node) {
team_name <- node %>%
html_element(".team-div .name") %>% # Select Team name element
html_text2() %>% # Retrieve the text
# Delete the points in the name
# Example: "Man City8pts" becomes "Man City"
str_remove(pattern ="\\d+\\spts?")
team_logo <- node %>%
# Select the img element which contains team logo
html_element(".logo img") %>%
# Retrieve the src attribute
html_attr("src") %>%
str_remove("&w=56")
# Return it like a tibble
tibble(
team_name,
team_logo
)
}Thanks to the purrr library, we can now retrieve all clubs names and logos.
clubs_names_logos <- clubs_rows %>%
map_df(extract_name_logo)| team_name | team_logo |
|---|---|
| Man. City | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/382.png |
| Liverpool | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/364.png |
| Arsenal | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/359.png |
| Tottenham | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/367.png |
| Chelsea | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/363.png |
| Man. United | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/360.png |
| Brighton | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/331.png |
| Newcastle | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/361.png |
| Crystal Palace | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/384.png |
| Brentford | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/337.png |
| Aston Villa | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/362.png |
| West Ham | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/371.png |
| Leeds United | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/357.png |
| Fulham | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/370.png |
| Southampton | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/376.png |
| Wolves | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/380.png |
| Everton | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/368.png |
| Leicester | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/375.png |
| Bournemouth | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/349.png |
| Nottm Forest | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/393.png |
Retrieve the forecast table
In this section, we will use another function from rvest package : html_table(). This function mimics what what a browser does, but repeats the values of merged cells in every cell that cover.
clubs_predictions <- league_link %>%
read_html() %>%
html_element("#forecast-table") %>%
# Don't keep the header
html_table(header = F) %>%
# Remove extra headers that we don't need
# And make the third row the columns names
janitor::row_to_names(row_number = 3) %>%
# Remove extra columns that we don't need
select(1:10) %>%
mutate(
# Delete the points in the name
# Example: Man City8pts becomes Man City
team_name = str_remove(team ,pattern ="\\d+\\spts?")
) %>%
relocate(team_name) %>%
select(-team)I know it can be a little bit complex for a beginner (6 months ago I was too). But nothing exceptional, if you understand the logic behind each function.
What the data looks like at this stage?
| team_name | spi | off. | def. | goal diff. | proj. pts.pts. | Every position | relegatedrel. | qualify for UCLmake UCL | win Premier Leaguewin league |
|---|---|---|---|---|---|---|---|---|---|
| Man. City | 93.0 | 3.0 | 0.3 | +64 | 87 | <1% | 96% | 66% | |
| Liverpool | 89.0 | 2.8 | 0.5 | +45 | 75 | <1% | 76% | 15% | |
| Arsenal | 81.5 | 2.3 | 0.6 | +25 | 71 | <1% | 59% | 8% | |
| Tottenham | 81.7 | 2.4 | 0.6 | +26 | 69 | <1% | 55% | 6% | |
| Chelsea | 81.3 | 2.2 | 0.5 | +14 | 64 | <1% | 35% | 3% | |
| Man. United | 75.9 | 2.1 | 0.7 | +7 | 61 | 1% | 25% | 1% | |
| Brighton | 76.3 | 2.0 | 0.6 | +10 | 60 | 1% | 24% | 1% | |
| Newcastle | 72.9 | 1.9 | 0.7 | +1 | 51 | 6% | 7% | <1% | |
| Crystal Palace | 70.2 | 1.8 | 0.8 | -5 | 48 | 10% | 5% | <1% | |
| Brentford | 68.8 | 2.0 | 0.9 | -4 | 48 | 10% | 4% | <1% | |
| Aston Villa | 71.0 | 1.8 | 0.7 | -8 | 48 | 11% | 3% | <1% | |
| West Ham | 71.1 | 1.8 | 0.7 | -8 | 45 | 15% | 2% | <1% | |
| Leeds United | 64.7 | 1.9 | 1.0 | -13 | 45 | 16% | 2% | <1% | |
| Fulham | 61.7 | 1.7 | 1.0 | -15 | 44 | 16% | 2% | <1% | |
| Southampton | 63.9 | 1.8 | 1.0 | -17 | 42 | 23% | 1% | <1% | |
| Wolves | 67.2 | 1.7 | 0.8 | -14 | 42 | 23% | 1% | <1% | |
| Everton | 64.4 | 1.7 | 0.9 | -15 | 41 | 25% | <1% | <1% | |
| Leicester | 67.1 | 2.0 | 1.0 | -18 | 41 | 27% | <1% | <1% | |
| Bournemouth | 54.7 | 1.5 | 1.1 | -38 | 35 | 49% | <1% | <1% | |
| Nottm Forest | 54.2 | 1.5 | 1.2 | -38 | 30 | 68% | <1% | <1% |
Let’s clean the data a bit more to make it fit what we want to do.
clubs_predictions <- clubs_predictions %>%
# the column with "win league" has different
# name according to the league so I rename it
# to "win_league" for all leagues
mutate(across(contains("win league"), ~ ., .names = "win_league")) %>%
# Rename important columns
rename(goal_diff = "goal diff.",
proj_pts = "proj. pts.pts.",
qualify_ucl = "qualify for UCLmake UCL"
) %>%
# Delete columns with space in their names
select(-contains(" "))
# When probability <1%, give it 0
clubs_predictions <- clubs_predictions %>%
mutate(across(.cols = c("relegatedrel.", "qualify_ucl", "win_league"), .fns = ~ if_else(. == "<1%", "0", .))) %>%
mutate(across(.cols = c("relegatedrel.", "qualify_ucl", "win_league"), .fns = ~ parse_number(.)))Finally, let’s join the clubs predictions dataframe with names and logos dataframe previously scraped.
clubs_predictions <- clubs_predictions %>%
left_join(clubs_names_logos)| team_name | spi | off. | def. | goal_diff | proj_pts | relegatedrel. | qualify_ucl | win_league | team_logo |
|---|---|---|---|---|---|---|---|---|---|
| Man. City | 93.0 | 3.0 | 0.3 | +64 | 87 | 0 | 96 | 66 | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/382.png |
| Liverpool | 89.0 | 2.8 | 0.5 | +45 | 75 | 0 | 76 | 15 | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/364.png |
| Arsenal | 81.5 | 2.3 | 0.6 | +25 | 71 | 0 | 59 | 8 | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/359.png |
| Tottenham | 81.7 | 2.4 | 0.6 | +26 | 69 | 0 | 55 | 6 | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/367.png |
| Chelsea | 81.3 | 2.2 | 0.5 | +14 | 64 | 0 | 35 | 3 | https://secure.espn.com/combiner/i?img=/i/teamlogos/soccer/500/363.png |
Data Visualization
Well, we had our data, tidy as we wanted. Now let’s visualize it. If you skip the scraping workflow, you can download the data for this section Here.
We are going to visualize it as a facet of a waffle plot for each team. Since the probabilities are represented as percentage, we are going to make a waffle of 100 squares. Each represents a chance for a club to win the league, to qualify for UEFA Champions League or both.
However, to fill the square according to each category of probability, it is necessary to wrangle the data a little bit more, in particular to bring together in a single column the three categories we want to highlight.
So what do I do?
predictions_waffle_df <- clubs_predictions %>%
mutate(ucl_qualif_diff = qualify_ucl - win_league,
remaining = 100 - qualify_ucl) %>%
pivot_longer(
cols = c("win_league", "ucl_qualif_diff","remaining"),
names_to = "win_cat",
values_to = "win_value"
)First, I create two new columns:
ucl_qualif_diffwhich represents the probability that a club qualifies to UEFA Champions Leagueremainingwhich represents the probability that a club won’t win the league and won’t qualify for the UEFA Champions League.
And finally, i am grouping my three categories into a single column win_cat and their values in the win_value column.
So let’s finally make the waffle.
We will be using waffle package by Bob Rudis, which is clearly one of my favorites.
Unfortunately, the package is not available on CRAN, so let’s install it with devtools:
devtools::install_github("hrbrmstr/waffle")We will need a few more packages to polish our visualization:
library(waffle)
library(ggtext) # For customize the text
library(ragg) # For the device to save the plotTo draw club logo images, let’s define a special function:
# The function takes 2 parameters
# x which refers to club logo link we scraped early
# width for the img width with default value 30
link_to_img <- function(x, width = 30) {
# Define the logo link as src attribute to
# html img element
glue::glue("<img src='{x}' width='{width}'/>")
}Finally let’s implement our visualization.
plot <- predictions_waffle_df %>%
mutate( team_name = fct_reorder(paste0(link_to_img(team_logo),'<br>',team_name), -qualify_ucl),
win_cat = fct_relevel(win_cat, c("win_league", "ucl_qualif_diff","remaining"))) %>%
ggplot(aes(fill = win_cat, values = win_value)) +
geom_waffle(color = "#111111", size = .15, n_rows = 10, flip = T) +
facet_wrap(vars(team_name)) +
scale_fill_manual(
name = NULL,
values = c(
"win_league" = "#117733",
"ucl_qualif_diff" = alpha("#117733",.5),
"remaining" = alpha("#117733",.1)
) ,
labels =
c(
"win_league" = "Win League & Qualify to UCL",
"ucl_qualif_diff" = "Qualify to UCL",
"remaining" = "No chance"
)
) +
labs(title = "English Premier League Clubs Predictions") +
coord_equal(expand = F) +
theme_minimal(base_family = "Chivo") +
theme(
plot.background = element_rect(fill = "grey95", color = NA),
panel.border = element_rect(color = "black", size = 1.1, fill = NA),
legend.position = "top",
plot.margin = margin( b = 1, unit = "cm"),
plot.title = element_text(size = rel(2), margin = margin(t = 20, b= 20)),
axis.text = element_blank(),
strip.text = element_markdown())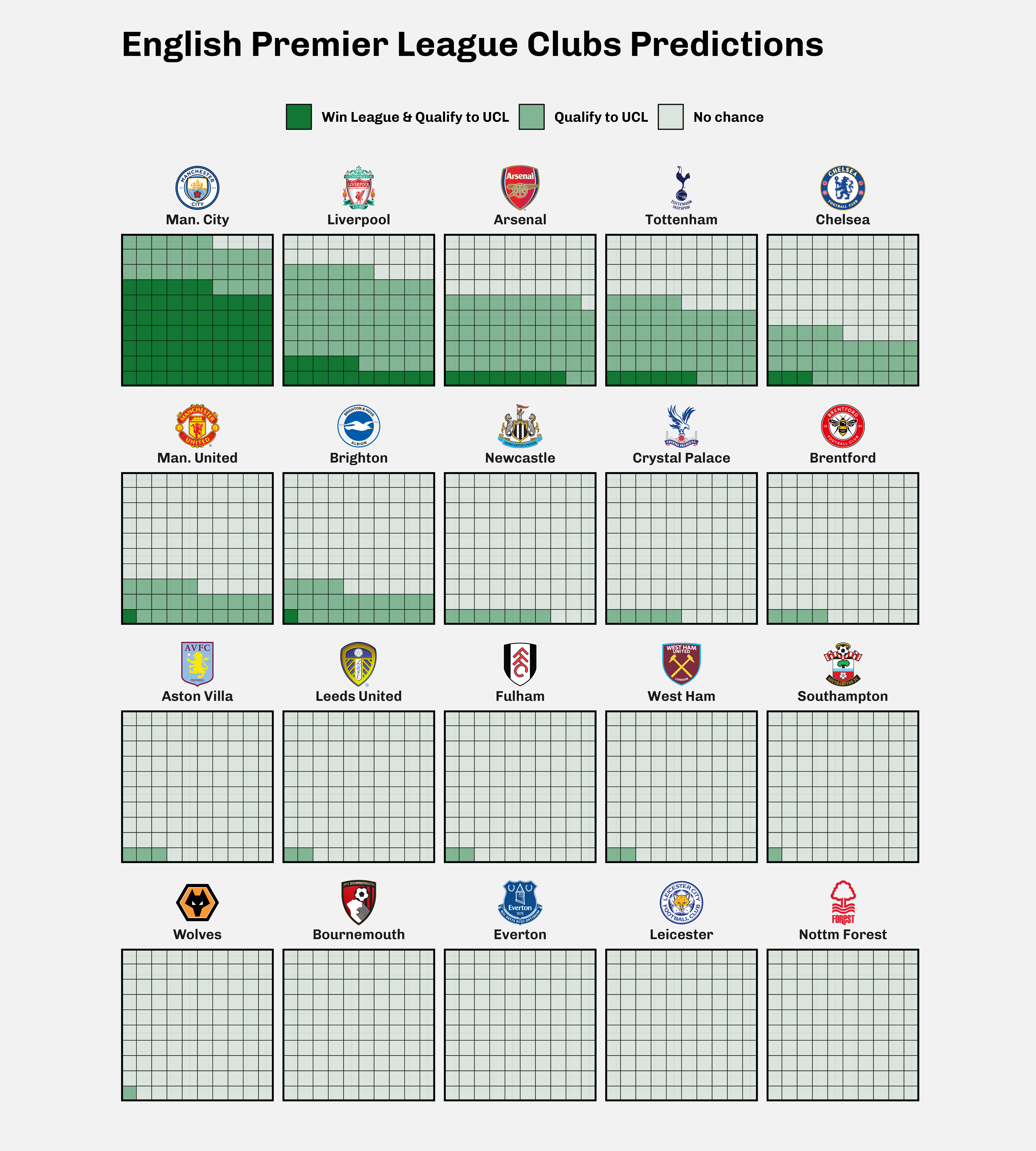
References
Footnotes
UEFA Champions League↩︎
Citation
@online{issabida2021,
author = {Abdoul ISSA BIDA},
title = {Club {Predictions}},
date = {2021-09-03},
url = {https://www.abdoulblog.com},
langid = {en}
}